Introduction — Le vrai problème n’est souvent pas le dashboard
Dans beaucoup de PME, un projet BI démarre de manière très pragmatique.
Tu connectes Power BI, Metabase ou un autre outil directement à un CRM, un ERP, quelques fichiers Excel, parfois une API SaaS, et tu obtiens rapidement un premier tableau de bord.
Au début, tout semble bien se passer. Les chiffres remontent, les équipes métier voient enfin quelque chose de concret, et le projet donne l’impression d’avancer vite.
Puis les premiers signaux faibles apparaissent :
- les dashboards deviennent instables
- les chiffres varient d’un rapport à l’autre
- les exports Excel se multiplient
- certaines analyses dépendent encore de connexions directes aux APIs
- chaque nouveau besoin ajoute une couche de bricolage
Le problème n’est pas uniquement l’outil de BI.
Dans la majorité des cas, le point de fragilité vient de l’architecture data :
- la donnée circule sans structure claire
- les transformations sont dispersées
- personne ne sait vraiment où se trouve la version fiable d’un indicateur
Autrement dit : tu n’as pas un problème de dashboard. Tu as un problème de fondation.
L’objectif de cet article est simple : te montrer comment construire une architecture data simple pour PME, crédible techniquement, facile à maintenir, et suffisamment robuste pour faire de la BI sérieuse sans basculer dans une usine à gaz.
ℹ️ Si tu travailles déjà avec Talend ou Talaxie, tu peux aussi lire mon article sur la manière dont les entreprises automatisent leurs données sans infrastructure complexe.
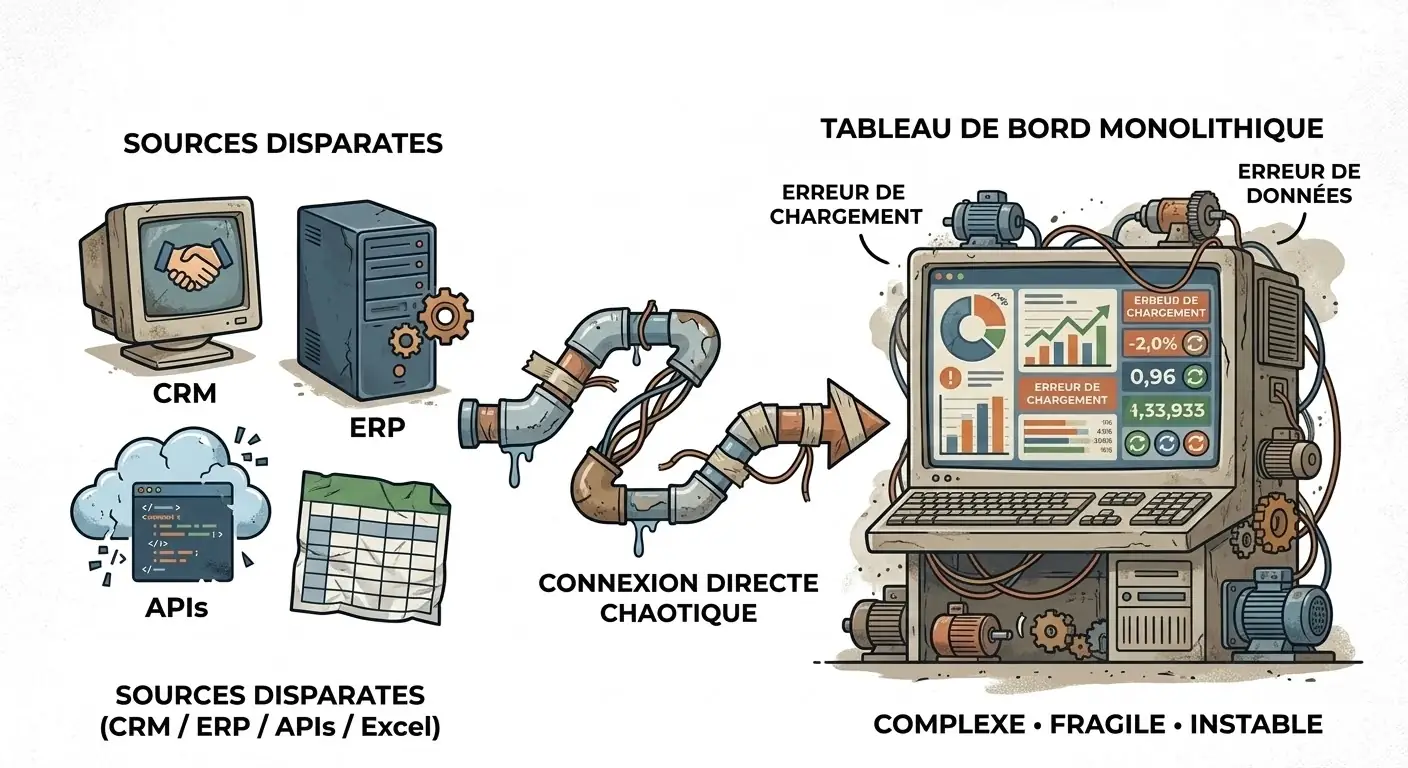
Le problème classique des projets BI
Pourquoi autant d’entreprises connectent-elles directement leurs dashboards aux sources ?
Parce que c’est le chemin le plus court.
Sources (CRM / ERP / APIs / Excel)
↓
BI Tool
Sur le papier, c’est rapide.
En pratique, ce modèle déplace toute la complexité dans la dernière couche du système. L’outil BI se retrouve alors à faire trois métiers en même temps :
- se connecter aux sources
- transformer les données
- restituer les indicateurs
C’est précisément là que les ennuis commencent.
Pourquoi ce modèle casse vite
Quand les transformations sont faites dans l’outil BI, la logique métier se disperse dans des requêtes, des colonnes calculées, des mesures ou des scripts de préparation difficiles à relire.
Tu obtiens alors :
- des performances irrégulières
- une maintenance compliquée
- des règles métier dupliquées
- aucune vraie centralisation des données
- une dépendance forte à la personne qui “connaît le fichier”
Le problème devient encore plus visible quand tu ajoutes une nouvelle source, un nouveau KPI ou un nouveau dashboard. Ce qui devait être simple finit par devenir fragile.
Si ton rapport doit à la fois interroger une API, corriger les données, recoller les référentiels et calculer la marge, tu n’as pas seulement un dashboard.
Tu as un pipeline de données caché dans la BI.
Et ce n’est pas le bon endroit pour ça.
L’architecture data recommandée
Pour une PME, une architecture robuste peut rester simple.
L’idée n’est pas de reproduire une plateforme data de grand groupe. L’idée est de séparer proprement les responsabilités.
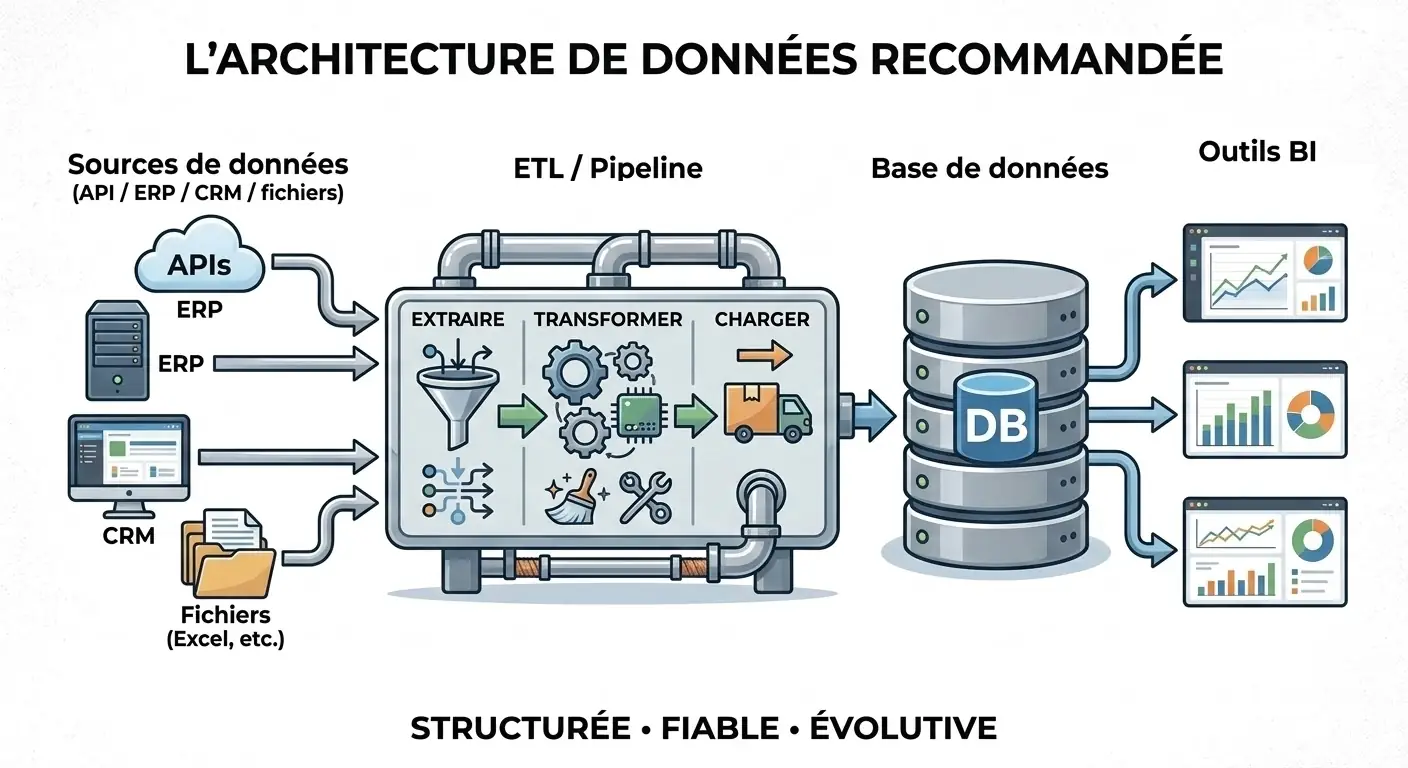
Cette architecture BI suit une logique claire :
- les sources produisent les données
- le pipeline de données les extrait et les prépare
- la base centrale stocke une version consolidée
- l’outil BI consomme des données déjà prêtes
C’est ce découpage qui change tout.
Tu cesses de bricoler des rapports “intelligents” pour construire un système data plus lisible, plus stable et plus évolutif.
Pourquoi cette approche fonctionne mieux
Elle apporte trois bénéfices immédiats.
1) Fiabilité
Tu évites que chaque dashboard réinvente sa propre logique métier.
2) Maintenabilité
Quand une API change, quand un champ évolue ou quand une source devient instable, tu corriges le pipeline à un seul endroit.
3) Évolutivité
Tu peux ajouter un nouvel indicateur, une nouvelle source ou un nouvel outil BI sans refaire toute la tuyauterie du projet.
En clair : tu remplaces un empilement de connexions fragiles par une architecture data lisible.
Les couches de l’architecture, une par une
Les sources de données
Dans une PME, les sources les plus fréquentes sont généralement les suivantes :
- CRM pour les clients, prospects et opportunités
- ERP pour les commandes, achats, stocks et facturation
- API SaaS pour le e-commerce, le paiement, la publicité ou le support
- fichiers Excel ou CSV
- bases existantes déjà présentes dans le SI
Le vrai sujet n’est pas seulement leur diversité.
C’est leur hétérogénéité.
Un CRM et un ERP n’utilisent pas forcément les mêmes identifiants. Une API peut évoluer sans prévenir. Un fichier Excel peut contenir des colonnes renommées à la main. Une base historique peut stocker les dates, les montants ou les statuts dans des formats incohérents.
C’est exactement pour cela qu’une source ne devrait presque jamais être exposée telle quelle au reporting.
La BI a besoin d’une donnée stable. Les systèmes métiers, eux, sont faits pour faire tourner l’activité, pas pour alimenter directement un modèle analytique propre.
ℹ️ Et si tes flux manipulent beaucoup de JSON, tu peux aussi lire ce guide sur la configuration de tWriteJSONField et du JSON Tree, particulièrement utile dès que les structures deviennent plus complexes.
Le rôle de l’ETL
ETL signifie Extraction, Transformation, Chargement.
Source → Transformation → Base de données
C’est la couche centrale du data engineering dans une architecture data simple.
Concrètement, un ETL comme Talend ou Talaxie peut gérer :
- l’extraction depuis plusieurs sources
- le nettoyage des données
- la normalisation des formats
- l’enrichissement par jointure
- la gestion des erreurs
- l’historisation
- le chargement dans une base cible
ℹ️ Si tu utilises Talaxie ou Talend au quotidien, tu peux compléter avec ce retour d’expérience sur la sécurisation de l’entrée du pipeline avec tSchemaComplianceCheck, très utile quand tu veux éviter que des données incohérentes polluent toute la chaîne.
Ce que l’ETL apporte vraiment
L’ETL ne sert pas juste à déplacer de la donnée.
Il sert à rendre la donnée exploitable.
Dans un projet data, les transformations les plus utiles sont souvent les plus concrètes.
Nettoyage
Supprimer ou corriger des valeurs nulles, des doublons, des libellés incohérents ou des formats incorrects.
Normalisation
Mettre toutes les dates, devises, statuts ou codes pays dans un format homogène.
Enrichissement
Associer plusieurs sources pour construire une vision métier utile.
Exemple : rapprocher un client CRM, une facture ERP et un paiement Stripe.
Gestion des erreurs
Isoler les lignes rejetées, tracer les anomalies, éviter qu’un lot entier tombe à cause de quelques enregistrements incorrects.
Historisation
Conserver l’évolution d’un état dans le temps au lieu d’écraser systématiquement la valeur précédente.
ℹ️ Si tu hésites encore sur l’environnement à utiliser, tu peux lire aussi Les différents Studios Talend : lequel choisir pour vos projets Data ?.
ETL ou ELT ?
La frontière entre ETL et ELT existe, mais pour une PME, ce n’est pas toujours le sujet principal.
Le point essentiel reste le même : la transformation ne doit pas vivre dans l’outil BI.
Que tu transformes avant ou après chargement selon ton contexte technique, l’objectif reste d’avoir une couche de préparation claire, pilotable et maintenable.
Et si tu es encore sur Talend Open Studio, le sujet de l’architecture se croise souvent avec celui de la pérennité de l’outillage. Dans ce cas, regarde aussi mon guide : Migration de Talend Open Studio vers Talaxie : guide complet en 8 étapes.
La base de données
Une fois les données extraites et transformées, tu as besoin d’un stockage central.
Cette base peut être :
- PostgreSQL
- SQL Server
- MySQL
- Ou une autre base adaptée à ton contexte
Tu n’as pas besoin d’un data warehouse “enterprise” pour commencer proprement.
Dans beaucoup d’entreprise, une base relationnelle bien structurée suffit largement pour centraliser les données, stabiliser les modèles et alimenter la BI dans de bonnes conditions.
Pourquoi cette couche est indispensable
Sans base centrale, tu n’as pas de source de vérité.
Chaque rapport lit alors sa propre version de la donnée, avec ses filtres, ses nettoyages et parfois ses approximations.
C’est là que les écarts apparaissent.
Avec une base de données centrale, tu peux structurer :
- des tables de staging pour les données brutes
- des tables métiers pour les données préparées
- des tables historisées pour suivre les évolutions
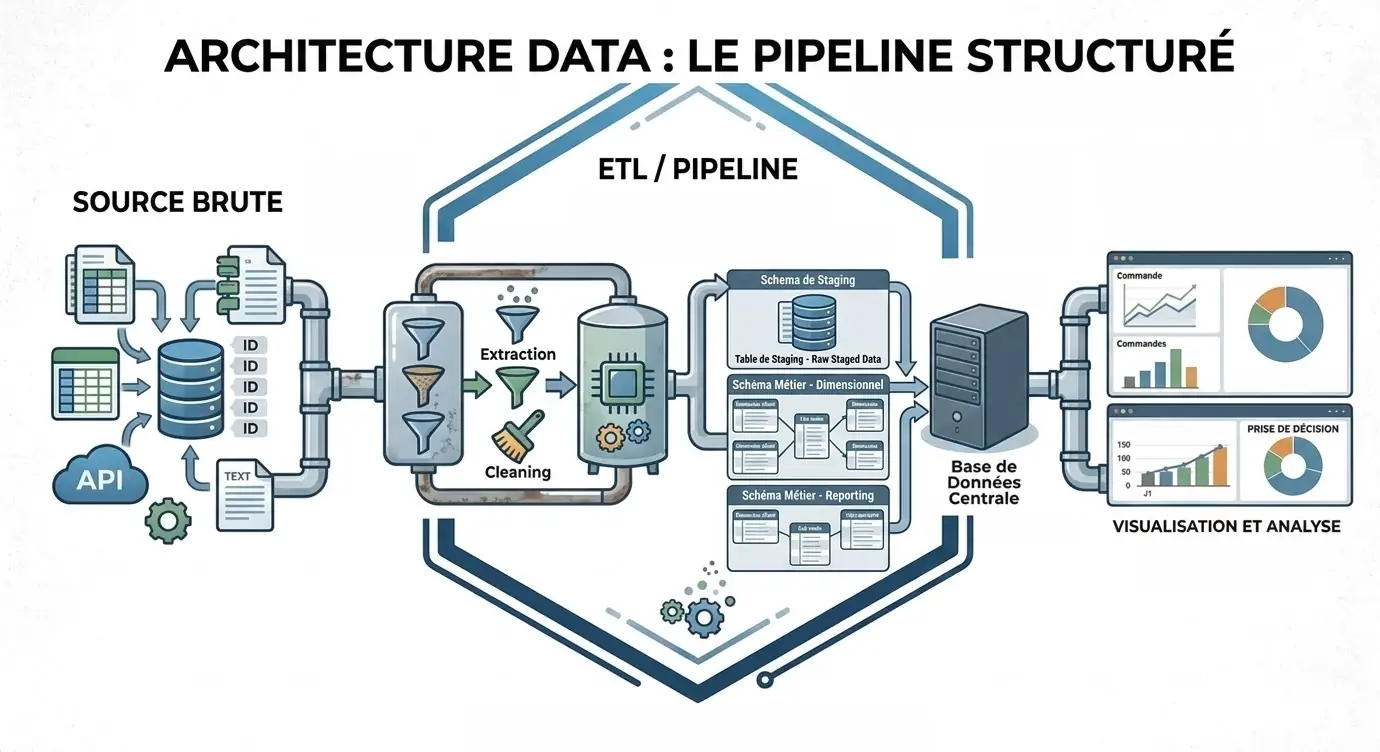
Ce découpage reste simple, mais il apporte une vraie lisibilité.
Tu sais où la donnée arrive, où elle est transformée, et où la BI doit se brancher.
L’outil de BI
L’outil BI est la dernière couche du système.
Il peut s’agir de :
- Power BI
- Metabase
- Superset
- Ou un autre outils adaptée à ton contexte
Son rôle est clair :
- afficher des indicateurs
- permettre l’analyse
- filtrer, comparer, explorer
- diffuser les tableaux de bord
En revanche, il ne devrait pas :
- reconstruire toute la logique métier
- corriger la qualité des données source
- porter seul les jointures complexes
- dépendre directement d’une API critique
Dit autrement : la BI doit consommer des données préparées, pas les fabriquer à la volée. C’est souvent à ce moment-là que le projet change de niveau. Tu passes d’un dashboard “qui marche plus ou moins” à une architecture BI qui tient dans le temps.
Exemple concret
Prenons un cas simple.
Une PME e-commerce travaille avec trois sources principales :
- Shopify API pour les commandes
- Stripe API pour les paiements
- ERP logistique pour les stocks et les expéditions
L’architecture cible peut ressembler à ceci :
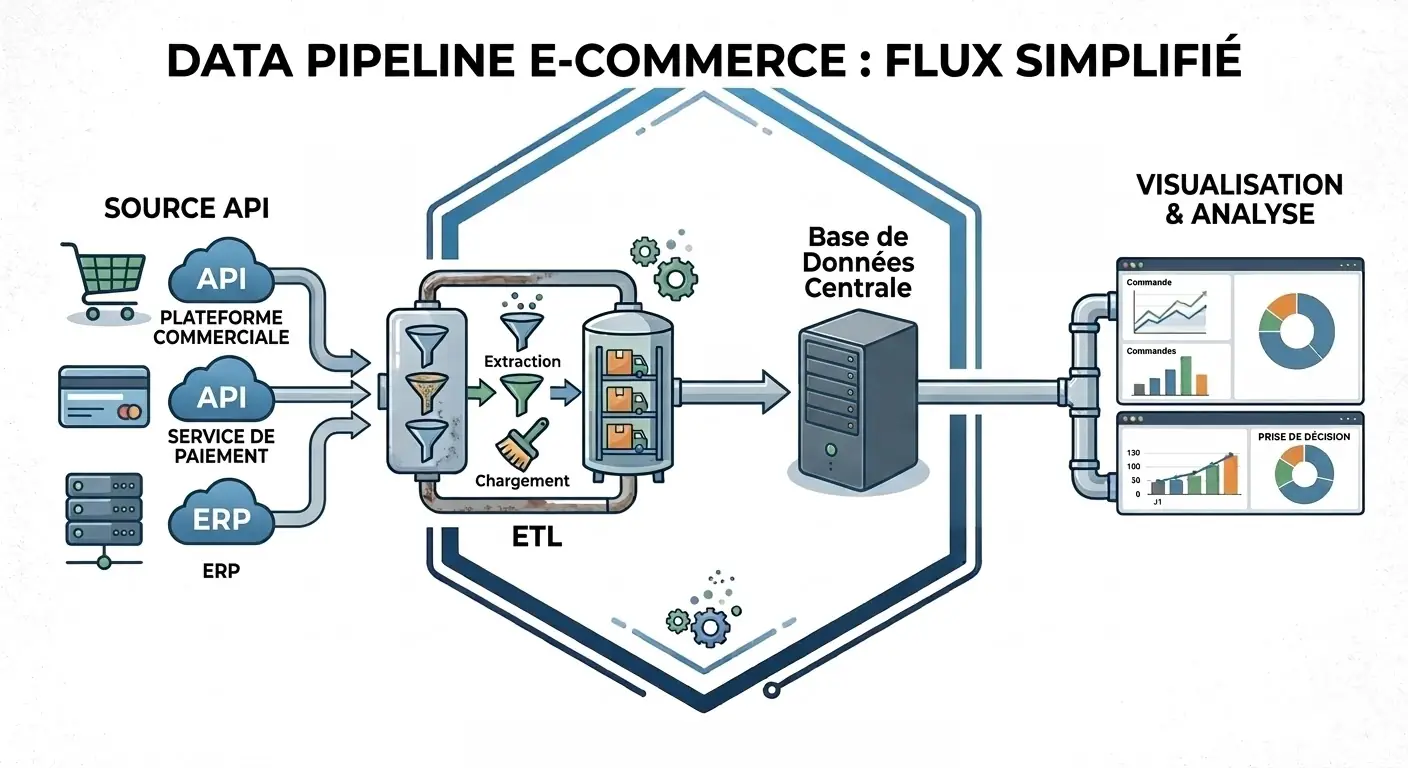
Ce que fait le pipeline
Le pipeline :
- récupère les commandes Shopify
- rapproche les paiements Stripe
- récupère les coûts et statuts logistiques dans l’ERP
- normalise les identifiants et les dates
- charge le tout dans PostgreSQL
Ce que la BI peut ensuite produire
Une fois les données centralisées, l’outil BI peut proposer des dashboards fiables sur :
- les ventes
- les marges
- la logistique
- la performance commerciale
La différence est majeure.
Le dashboard ne dépend plus directement de trois systèmes différents. Il lit une base centrale déjà préparée.
Résultat :
- les chiffres sont plus cohérents
- les temps de réponse sont plus prévisibles
- les règles métier sont plus faciles à maintenir
- l’ajout d’un nouveau KPI devient beaucoup moins risqué
ℹ️ Quand les flux deviennent événementiels ou doivent dialoguer avec des services externes, il faut aussi bien distinguer logique d’API et logique de notification. J’ai détaillé ce point ici : API vs Webhook : comprendre la différence et implémenter un webhook sécurisé avec Talaxie.
Les erreurs les plus fréquentes
Voici les erreurs que l’on retrouve le plus souvent dans les projets d’architecture data et de BI en entreprise.
1) Transformer les données dans l’outil BI
C’est le raccourci le plus fréquent.
Au départ, ça va vite. Ensuite, la logique métier se disperse, les performances se dégradent, et la maintenance devient pénible.
2) Se connecter directement aux APIs
Tu rends ton reporting dépendant de la disponibilité, de la latence, du quota et parfois du format de réponse de l’API.
C’est pratique pour un test. C’est fragile pour un système de pilotage.
3) Multiplier les fichiers Excel intermédiaires
Tu perds la traçabilité, tu crées des versions concurrentes et tu compliques la gouvernance de la donnée.
4) Ne pas gérer les logs ETL
Sans logs ni gestion d’erreurs, tu découvres les problèmes uniquement quand un utilisateur te dit que “les chiffres ont l’air bizarres”.
Autant dire que ce n’est pas le meilleur système d’alerte du marché.
5) Ne pas historiser les données
Si tu écrases toujours l’état courant, tu perds la capacité d’expliquer une évolution dans le temps.
Et sans historique, beaucoup d’analyses métiers deviennent incomplètes.
Comment démarrer sans sur-ingénierie
Tu n’as pas besoin de tout refaire d’un coup.
Le plus efficace est souvent de procéder par étapes.
Étape 1 — Identifier les sources critiques
Commence par les 2 ou 3 sources qui alimentent les indicateurs les plus importants.
Étape 2 — Sortir les transformations du dashboard
Tout ce qui relève du nettoyage, du rapprochement ou de la normalisation doit migrer vers le pipeline.
Étape 3 — Créer une base centrale simple
Même une base relationnelle bien structurée peut déjà faire une énorme différence.
Étape 4 — Brancher la BI sur des tables préparées
Le dashboard doit lire des données déjà stabilisées, pas improviser leur préparation.
Étape 5 — Ajouter des logs et un minimum d’historique
C’est souvent ce qui fait la différence entre un pipeline “qui marche aujourd’hui” et un pipeline maintenable.
FAQ — Architecture data, ETL et BI en PME
Faut-il une architecture data complète dès le début ?
Non. En PME, l’objectif n’est pas de construire une plateforme data complexe dès le départ. Le plus important est de poser une structure simple et saine : sources → ETL → base de données → BI.
Tu peux très bien commencer avec quelques sources critiques, un pipeline clair et une base relationnelle bien structurée. Le vrai enjeu n’est pas la sophistication technique, mais la fiabilité de la donnée et la capacité à faire évoluer le système sans casser les dashboards.
Peut-on connecter directement Power BI ou Metabase aux sources ?
Oui, techniquement, mais ce n’est généralement pas une bonne idée dès que le besoin devient un peu sérieux.
Pour un prototype ou un test rapide, ça peut suffire. En revanche, dès que plusieurs sources, transformations métier ou indicateurs stratégiques entrent en jeu, ce modèle devient vite fragile : performances irrégulières, logique métier dispersée, maintenance difficile, absence de source de vérité.
Une PME a-t-elle vraiment besoin d’un ETL ?
Dans beaucoup de cas, oui.
Dès que tu dois récupérer des données depuis plusieurs outils, nettoyer les formats, rapprocher des référentiels ou historiser des états, un ETL devient très utile. Il permet de sortir cette logique de l’outil BI et de la rendre plus stable, plus lisible et plus maintenable.
Quelle base de données choisir pour centraliser les données ?
Pour une PME, une base relationnelle bien connue suffit souvent largement.
PostgreSQL, SQL Server ou MySQL peuvent très bien faire le travail selon ton contexte, tes compétences internes et ton existant. Le point clé n’est pas d’avoir la technologie la plus “impressionnante”, mais d’avoir un stockage central propre, cohérent et exploitable par la BI.
Quelle différence entre ETL et ELT ?
La différence tient au moment où la transformation est faite.
- ETL : tu extrais, tu transformes, puis tu charges
- ELT : tu extrais, tu charges, puis tu transformes dans la cible
En pratique, pour une PME, le plus important n’est pas le sigle. Le vrai sujet est de ne pas laisser les transformations critiques vivre directement dans l’outil BI.
Quand faut-il passer d’un dashboard “rapide” à une vraie architecture BI ?
Dès que tu observes un ou plusieurs de ces signaux :
- les chiffres diffèrent selon les rapports
- les exports Excel se multiplient
- une API ou un fichier casse régulièrement le reporting
- les temps de chargement deviennent imprévisibles
- un seul fichier ou une seule personne “détient” la logique métier
À ce moment-là, tu n’as plus seulement un besoin de visualisation. Tu as un besoin d’architecture.
Quelle est l’erreur la plus fréquente dans un projet BI PME ?
La plus fréquente, c’est de transformer l’outil BI en ETL caché.
Au début, c’est rapide. Ensuite, tout devient plus dur : maintenance, performance, évolution, gouvernance, onboarding d’un nouveau collègue ou d’un prestataire. Une BI efficace consomme des données préparées, elle ne devrait pas être l’endroit où toute la logique de préparation est reconstruite.
Peut-on mettre en place une architecture data simple sans équipe data dédiée ?
Oui, à condition de rester pragmatique.
Une PME n’a pas forcément besoin d’un data engineer à temps plein ni d’une stack complexe. En revanche, elle a besoin d’un minimum de méthode : identifier les sources critiques, fiabiliser les flux, centraliser les données utiles et brancher la BI sur des tables propres.
ℹ️ Aller plus loin sur BMData
Si tu veux approfondir le sujet ou comparer cette approche avec d’autres cas concrets, voici quelques ressources utiles :
- Talend/Talaxie : comment les entreprises automatisent leurs données sans infrastructure complexe
- Migration de Talend Open Studio vers Talaxie : guide complet en 8 étapes
- Les différents Studios Talend : lequel choisir pour vos projets Data ?
- Talaxie : sécuriser l’entrée du pipeline avec tSchemaComplianceCheck
- Talaxie : bien configurer tWriteJSONField et le JSON Tree
- API vs Webhook : comprendre la différence et implémenter un webhook sécurisé avec Talaxie
Si tu veux aller au-delà des concepts et structurer un cas réel :
Conclusion
Une bonne architecture data n’a pas besoin d’être compliquée.
Le message clé reste le même : Sources → ETL → Base de données → BI.
Cette structure simple permet de construire une architecture BI plus saine, avec :
- une meilleure fiabilité des données
- une vraie centralisation des données
- une meilleure maintenabilité
- une base plus solide pour faire évoluer le système
Si tu veux que ton outil BI reste un outil d’analyse, ne lui demande pas de devenir en même temps :
- un ETL caché
- une base de données improvisée
- un atelier de correction des données
En data engineering comme ailleurs, ce qui est simple n’est pas forcément basique. Souvent, c’est juste ce qui tient le mieux dans le temps.
Et dans un projet BI, c’est souvent là que se joue la différence entre un dashboard “joli” et un système de pilotage réellement fiable.
Si tu veux fiabiliser tes dashboards, clarifier tes flux ou remettre de l’ordre entre tes sources, ton ETL et ta BI, c’est généralement à ce niveau que les gains les plus rapides apparaissent.
Tu peux aussi :
- découvrir mes services Talend & Talaxie
- voir mes services Power BI
- ou parcourir mes réalisations data & automatisation
Note sur les visuels : les illustrations de cet article ont été générées avec l’aide de l’IA (Gemini), puis sélectionnées et intégrées par BMData pour accompagner la lecture.
Sources
- Microsoft Learn — Architecture de solution BI dans le Centre d’excellence
- Microsoft Learn — Découvrez le schéma en étoile et son importance pour Power BI
- Microsoft Learn — DirectQuery dans Power BI
- Qlik / Talend Help — Architecture fonctionnelle de Talend Data Integration
- Qlik / Talend Help — Gestion des erreurs dans Studio Talend
- AWS — Qu’est-ce que l’ETL ?
- AWS — ETL et ELT : différence entre les approches de traitement des données