Le JSON est partout : NoSQL, API, événements, configs. Et dès que les structures se corsent (objets imbriqués, tableaux, types non-string), tWriteJSONField peut vite te faire transpirer.
Dans ce guide, je te montre comment garder la main, produire un JSON propre et exploitable, et surtout comprendre ce que fait le JSON Tree (au lieu de cliquer au hasard et espérer que ça passe).
Workspace prêt : [Lien] pour suivre pas à pas.
Si tu as déjà joué avec le JSON sur Talaxie (ou Talend), tu connais tWriteJSONField.
La différence entre un JSON “presque bon” et un JSON prêt à consommer, elle se joue dans les détails : loop element, class, group by, tri…
Au menu :
- Comprendre à quoi sert vraiment
tWriteJSONField - Configurer le JSON Tree selon le JSON cible
- Maîtriser les attributs
typeetclass(array/object) - Gérer les cas classiques : un objet par ligne, un tableau d’objets, des types non-string (
int,boolean, etc.)
Sources utiles :
- [Configurer une arborescence JSON]
- [Configurer le tWriteJSONField]
- [Propriétés du tWriteJSONField Standard]
Sommaire
- 1. À quoi sert vraiment tWriteJSONField ?
- 2. Comprendre le JSON Tree
- 3. Les attributs du JSON Tree
- 4. Construire le bon JSON
- 5. Rétrospective et mise en perspective
1. À quoi sert vraiment tWriteJSONField ?
tWriteJSONField transforme des lignes tabulaires en JSON, puis stocke ou transmet ce JSON :
- dans une colonne de la ligne (ex.
json_document,serializedValue), - ou vers un composant aval (
tRestClient, MongoDB, etc.).
En pratique, vois-le comme un atelier de montage :
- tu pars d’un schéma d’entrée classique,
- tu décris la structure JSON dans le JSON Tree,
- tu obtiens une chaîne JSON dans une colonne de sortie (Output Column), prête à être envoyée ou écrite.
👉 Le point important : tWriteJSONField ne “devine” rien.
Si ton schéma, ton flux et ton JSON cible ne racontent pas la même histoire, tu auras un JSON “bizarre”… et tu passeras du temps à le patcher.
La bonne approche : décrire clairement la cible, puis laisser le composant faire la traduction.
Les paramètres clés : Basic settings
Dans les Basic settings, retiens surtout :
- Colonne de sortie : où sera écrite la chaîne JSON (ex.
json_doc,serializedValue). - Configurer la structure JSON : ouvre le JSON Tree pour dessiner la structure (objets, tableaux), déclarer les types et fixer le loop element.
- Group by : regroupe plusieurs lignes d’entrée pour produire un seul JSON. Indispensable pour fabriquer un tableau ou un JSON agrégé par clé.
- Supprimer le nœud racine : retire la racine générée si la cible attend directement un tableau ou un objet.
👉 En clair : dis où écrire, comment structurer, si tu regroupes, et si tu gardes la racine. Le reste n’est que conséquences.
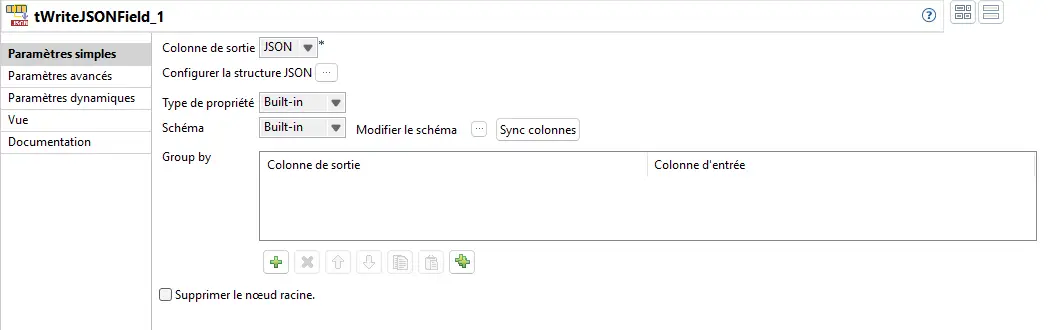
Les paramètres complémentaires : Advanced settings
- Entourer de guillemets toutes les valeurs non nulles : force tout en
String. - Passer les valeurs nulles en chaîne de caractères vide :
nulldevient"". - Utiliser la notation scientifique pour les valeurs flottantes : utile si l’aval l’exige.
⚠️ Attention : ces options “forcent” le résultat. Sur une API stricte ou un index NoSQL, cela peut casser la validation. À activer seulement si tu sais pourquoi.
À retenir
tWriteJSONFieldapplique exactement ce que tu décris dans le JSON Tree et via ses paramètres. Il ne devine rien.
2. Comprendre le JSON Tree (et ce qu’il représente vraiment)
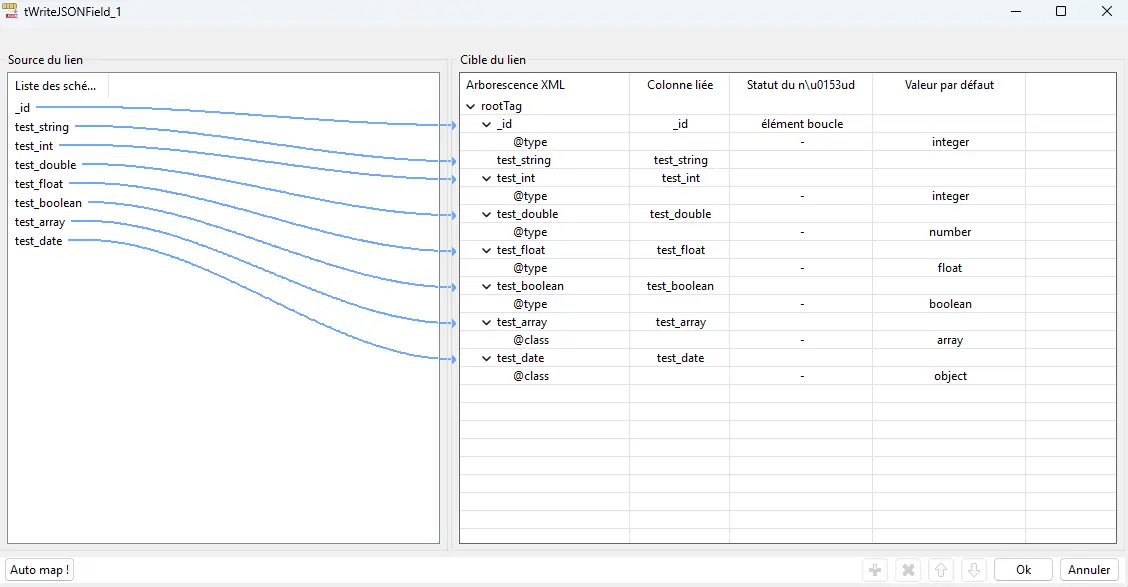
Quand tu cliques sur Configurer la structure JSON, tu ouvres le JSON Tree :
- à gauche : Source du lien → les colonnes d’entrée,
- à droite : Cible du lien → l’arbre JSON attendu,
- au centre : les liens de mapping par drag & drop.
Comment fonctionne réellement le JSON Tree
- Chaque nœud du JSON Tree correspond à un niveau de la structure JSON (objet, champ, tableau, sous-objet…).
- Tu choisis le loop element : celui qui se répète pour chaque ligne ou chaque élément d’un tableau.
- Tu ajoutes des attributs pour préciser le comportement :
type→ forcer le type de valeur (integer,number,float,boolean),class→ décrire la structure (arrayouobject).
Le point clé à retenir
Le JSON Tree n’est ni automatique ni intelligent.
Il suit exactement la structure et les attributs (type, class, loop) que tu poses. Il ne devine rien : tu décris précisément le JSON final.
💡 Astuce terrain : avant d’ouvrir l’éditeur, dessine le JSON cible (même vite fait).
Plus ta structure cible est claire, plus tu vas vite… et moins tu fais d’allers-retours.
3. Les attributs du JSON Tree : type et class
Par défaut, tWriteJSONField s’appuie sur le type des colonnes d’entrée :
Integer→ nombre JSON,Boolean→ booléen JSON,String→ chaîne JSON.
Dans les cas simples, aucun attribut n’est nécessaire.
Dès que la structure se complexifie (tableaux, objets imbriqués, regroupements, données calculées), les attributs deviennent tes garde-fous.
3.1. Attribut type : forcer ou corriger le type
Utile si : schéma trop générique (String partout), valeur calculée/concaténée, cible stricte (API, NoSQL, index).
Pour l’ajouter :
- Clic droit sur le nœud → Ajouter un attribut → Name :
type - Clic droit sur l’attribut → Définir une valeur fixe → Fixed value :
integer/number/float/boolean
Si ton schéma est proprement typé, laisse Talaxie gérer. Ajoute
typeseulement quand tu veux reprendre le contrôle.
3.2. Attribut class : décrire la structure (array / object)
class=array: le nœud est un tableau JSON. Il doit contenir un sous-nœud (souventelement) défini comme loop element.class=object: le nœud est un objet JSON servant de conteneur.
Un tableau sans
class=arrayou sans loop element = conception bancale (et JSON pénible à exploiter).
Pour l’ajouter :
- Clic droit sur le nœud → Ajouter un attribut → Name :
class - Clic droit sur l’attribut → Définir une valeur fixe → Fixed value :
array/object
En résumé : laisse les types faire leur travail quand le schéma est propre, et pose class dès qu’un tableau ou un objet doit être explicite. Ajoute les attributs pour lever un doute, pas “pour voir si ça marche”.
4. Construire le bon JSON : on commence par la cible
Cas concret de deux sources de données que l’on cherche à joindre : Personnes et Adresses.
4.1. Les données de départ (2 sources)
- Personnes (id unique)
- Adresses (0..n adresses par personne)
Personnes : structure
| Champ | Type Talaxie | Description |
|---|---|---|
| _id | Integer | Identifiant unique |
| nom | String | Nom |
| prenom | String | Prénom |
| telephone | String | Téléphone |
| age | Integer | Âge |
| actif | Boolean | Personne active ? |
Adresses : structure
| Champ | Type Talaxie | Description |
|---|---|---|
| _id | Integer | Identifiant unique de l’adresse |
| personnes_id | Integer | Référence vers la personne (_id) |
| numero | Integer | Numéro de rue |
| rue | String | Nom de la rue |
| ville | String | Ville |
| latitude | Double | Latitude |
| longitude | Double | Longitude |
| actif | Boolean | Adresse active ? |
4.2. Avant de toucher aux composants : répondre à 3 questions
1) Unité de sortie ?
- Un document par personne ?
- Ou un document global avec tout le monde ?
Ici, j’ai choisi un JSON global pour montrer les tableaux imbriqués et le rôle duGroup by.
2) Cardinalité Personne → Adresse ?
0, 1 ou plusieurs adresses. Donc côté JSON : un tableau adresses, même vide.
3) Organisation cible ?
- nœud racine global,
- tableau
personnes(loop principal), - pour chaque personne : ses champs + tableau
adresses(loop imbriquée).

La bonne stratégie
Décomposer :
- un
tWriteJSONFieldpour bâtir le tableau d’adresses, - un second pour l’insérer à côté des champs Personne.
👉 Pourquoi ? Parce que si tu “aplaties” tout trop tôt, tu passes ensuite ton temps à réparer des duplications au lieu de construire proprement.
4.3. Plan de construction (pas à pas)
- Étape A : construire le tableau d’adresses par personne.
- Étape B : rattacher ce tableau au flux Personnes sans dupliquer.
- Étape C : produire le JSON global final.
4.4. Réalisation des étapes
Prérequis : données d’exemple (tFixedFlowInput)
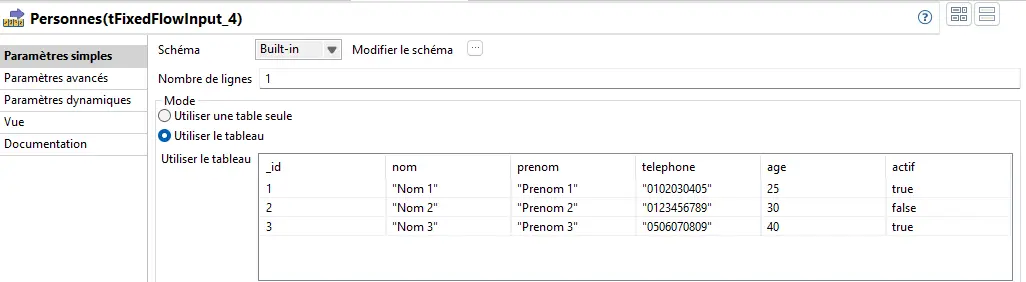
Personnes :
| _id | nom | prenom | telephone | age | actif |
|---|---|---|---|---|---|
| 1 | Nom 1 | Prenom 1 | 0102030405 | 25 | true |
| 2 | Nom 2 | Prenom 2 | 0123456789 | 30 | false |
| 3 | Nom 3 | Prenom 3 | 0506070809 | 40 | true |
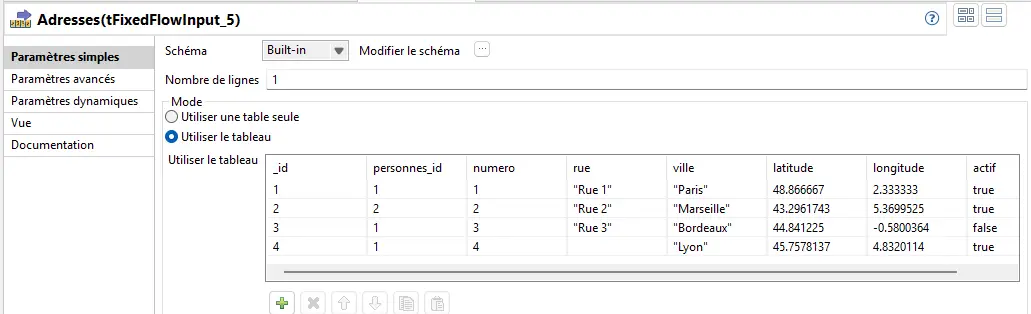
Adresses :
| _id | personnes_id | numero | rue | ville | latitude | longitude | actif |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | Rue 1 | Paris | 48.86667 | 2.333333 | true |
| 2 | 2 | 2 | Rue 2 | Marseille | 43.2961743 | 5.3699525 | true |
| 3 | 1 | 3 | Rue 3 | Bordeaux | 44.841225 | -0.5800364 | false |
| 4 | 1 | 4 | Rue 4 | Lyon | 45.7578137 | 4.8320114 | true |
4.5 Étape A : Construire le tableau d’adresses (par personne)
Objectif : à partir du flux Adresses, regrouper par personne pour obtenir personnes_id + json_adresses (chaîne contenant le tableau).
4.5.1 Préparer le flux “Adresses”
Vérifie : présence de personnes_id, types corrects, au moins une personne avec plusieurs adresses.
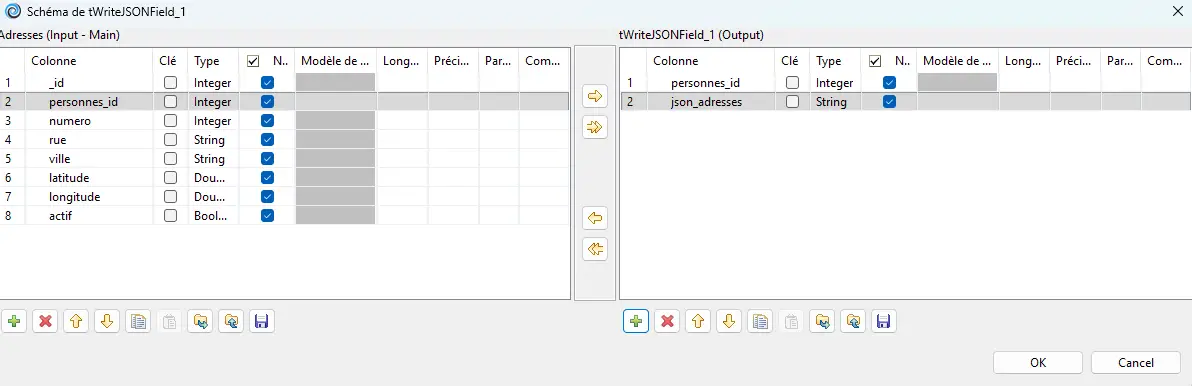
4.5.2 Ajouter un tWriteJSONField dédié
- Schéma de sortie : ajoute
json_adresses(String) et gardepersonnes_id. - Output Column :
json_adresses.
4.5.3 Régler le Group by
Dans Basic settings > Group by :
Input column=personnes_idOutput column=personnes_id
Traduction : pour chaque personnes_id, un seul résultat avec les lignes agrégées.
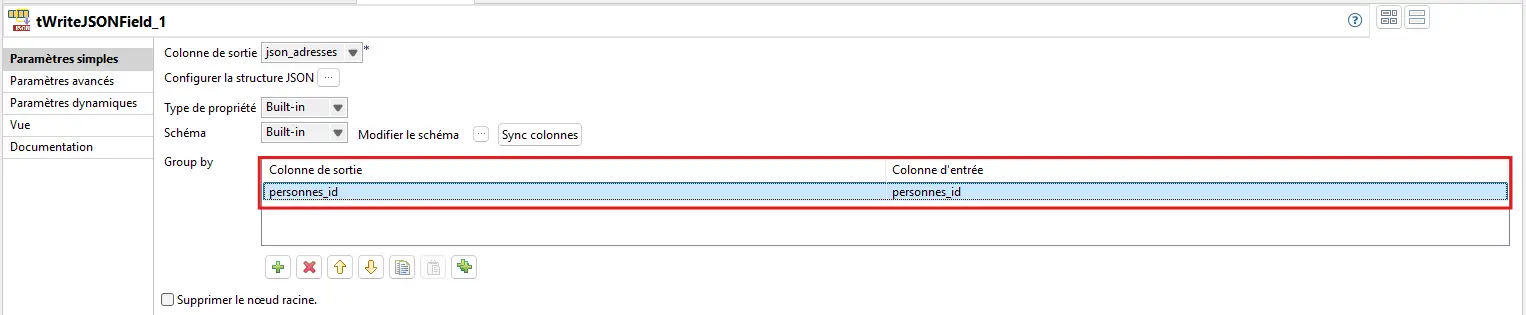
👉 Ce Group by est le cœur de l’étape A. Sans lui, tu ne fabriques pas un tableau d’adresses par personne mais autant de JSON qu’il y a de lignes.
C’est ici que tu choisis la granularité de sortie.
4.5.4 Configurer le JSON Tree adresses[]
Structure voulue : nœud racine (temporaire) → adresses (class=array) → adresse (loop, class=object) → champs.
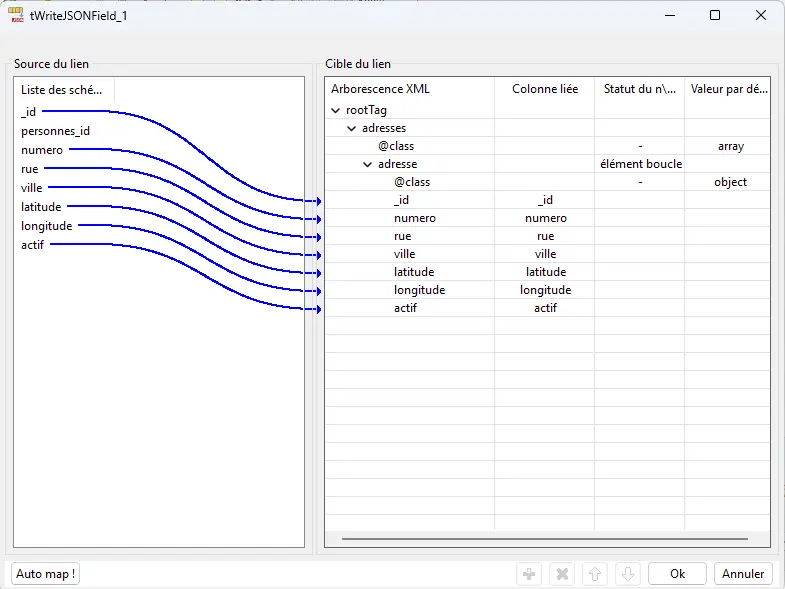
Champs sous adresse : _id, numero, rue, ville, latitude, longitude, actif.
Ne mets pas
personnes_id: il sert au regroupement, pas à la structure.
Mappe les colonnes par drag & drop. Si besoin, ajoute type pour forcer un nombre ou un booléen, mais seulement si le schéma n’est pas fiable.
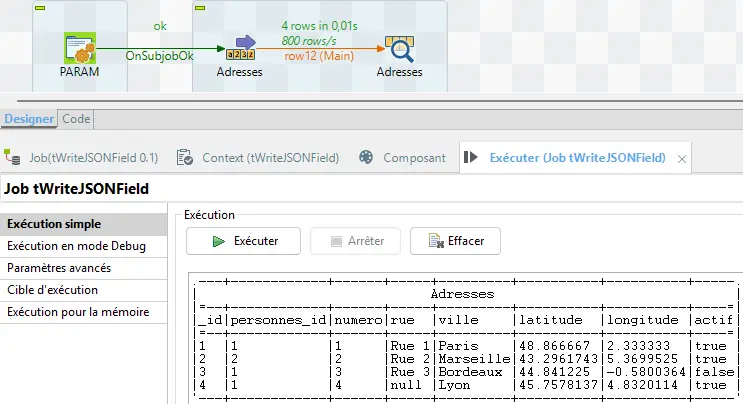
4.5.5 Exécuter et analyser
Lance : tFixedFlowInput (Adresses) → tWriteJSONField → tLogRow.
- Le nombre de lignes doit correspondre au nombre de
personnes_iddistincts.
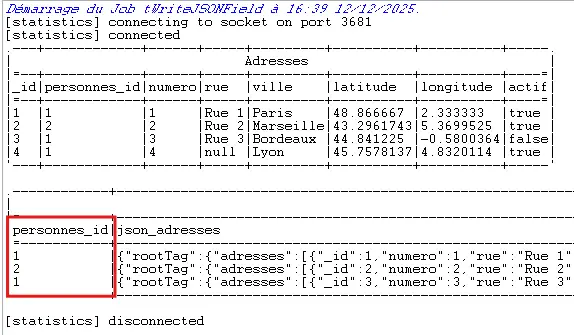
On voit ici un piège classique : trois lignes, séquence 1,2,1.
LeGroup bydetWriteJSONField(et d’autres composants) ne trie rien. Il regroupe uniquement les lignes consécutives. Si les données arrivent dans le désordre, le regroupement est faux.
On corrige donc : ajoute un tSortRow avant, tri ascendant sur personnes_id.
Après relance, chaque personne a son tableau d’adresses.
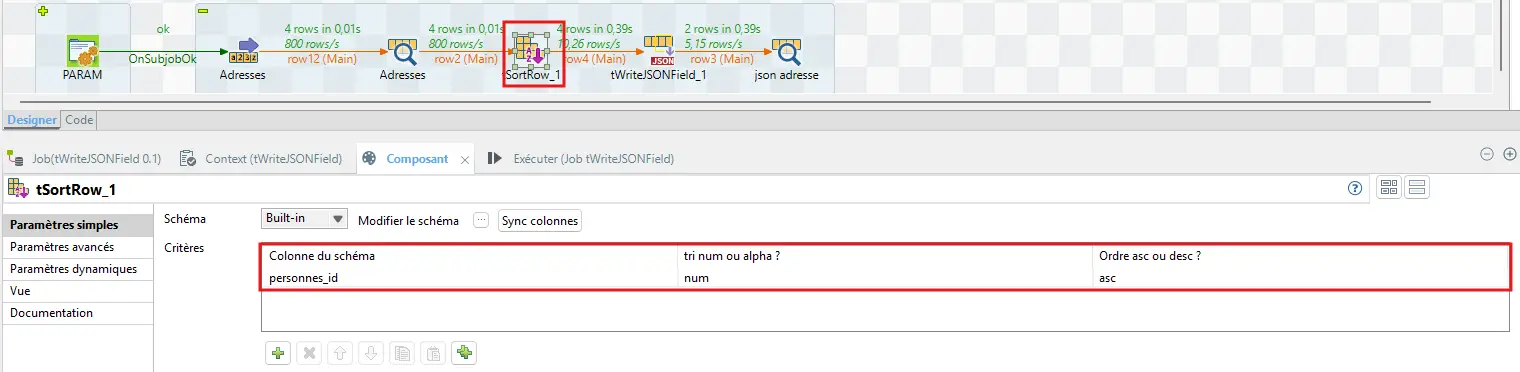
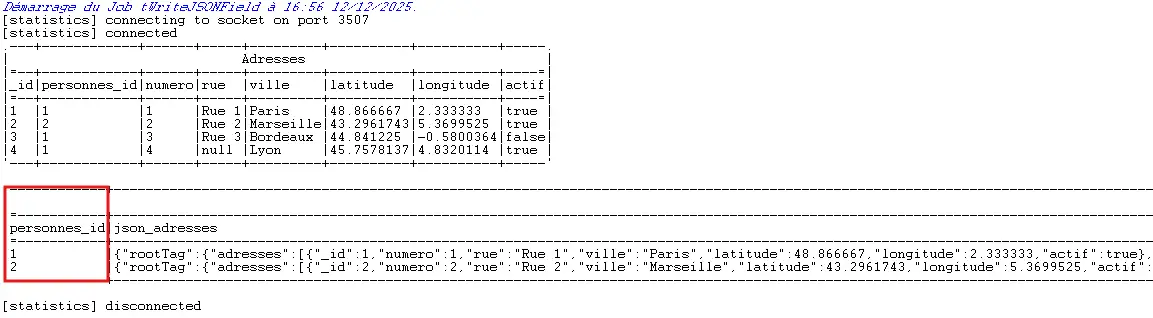
Contrôle la colonne json_adresses : tableau valide, bons champs, types cohérents. Pour affiner, coche Supprimer le nœud racine et, si besoin, mets class=object sur rue pour éviter des tableaux vides.

✅ Étape A validée : JSON Tree structuré, Group by maîtrisé, bloc
adresses[]prêt à être réutilisé.
4.6 Étape B : Rattacher le tableau d’adresses au flux Personnes (sans duplication)
Objectif : repartir du flux Personnes, y rattacher json_adresses, et sortir une seule ligne par personne.
4.6.1 Préparer les deux flux
1) Personnes (source brute)
2) Adresses agrégées (résultat étape A : personnes_id + json_adresses)
4.6.2 Jointure dans un tMap (LEFT JOIN)
- Main :
Personnes - Lookup : “Adresses agrégées”
- clé :
personnes._id=adresses.personnes_id - jointure : LEFT OUTER pour garder les personnes sans adresse.
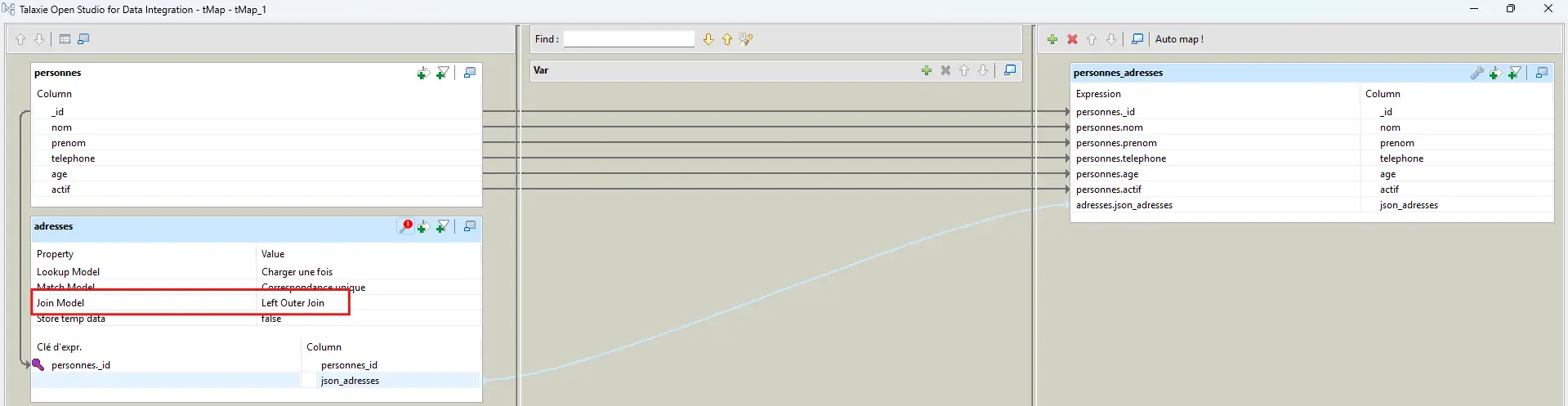
👉 Ici, le LEFT JOIN est non négociable : si tu passes en INNER, tu perds les personnes sans adresse et ton JSON final ne reflète plus la réalité métier.
Toujours valider la cardinalité attendue avant de mapper.
4.6.3 Schéma de sortie
Ressors : _id, nom, prenom, telephone, age, actif, json_adresses.
⚠️ Inutile de ressortir personnes_id du lookup : _id suffit.
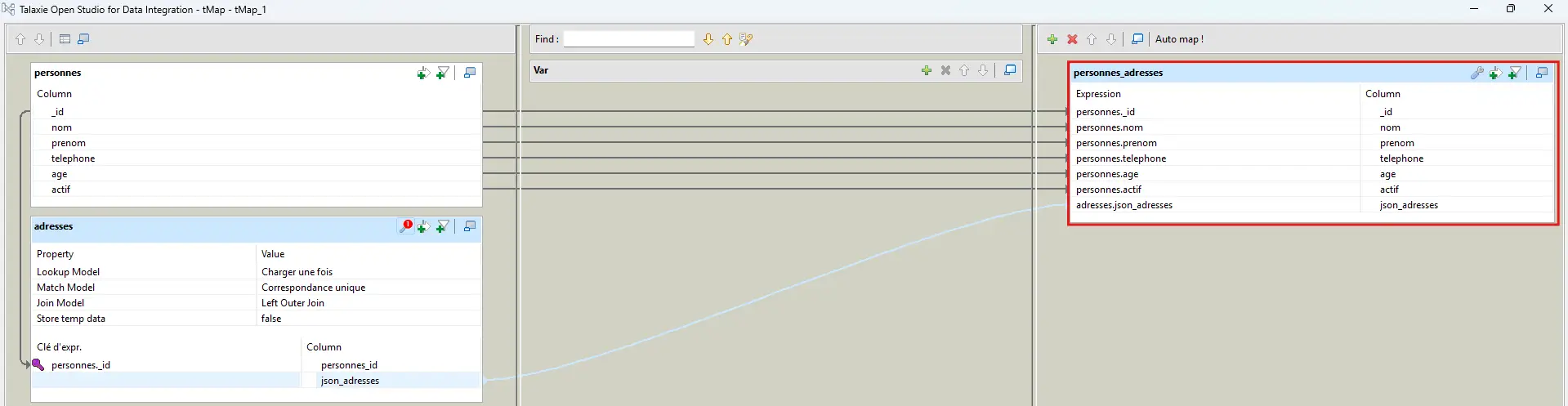
4.6.4 Gérer “aucune adresse”
Avec un LEFT JOIN, certaines personnes ont json_adresses = null. On veut un tableau, même vide.
Dans notre cas, ça tombe bien : tWriteJSONField peut interpréter une chaîne null et produire une structure vide conforme (selon la config du JSON Tree final). On s’assure surtout, à l’étape C, de rester cohérent : adresses doit toujours être un tableau.
4.6.5 Contrôler les duplications
tLogRow juste après le tMap :
- nombre de lignes = nombre de personnes (ici 3),
- chaque
_idapparaît une seule fois, json_adressescontient plusieurs éléments pour_id=1, un seul pour_id=2, vide pour_id=3.

4.7 Étape C : Construire le JSON global final
Objectif : à partir du flux “Personnes + json_adresses”, produire un seul document JSON avec tout le monde, sans duplication, dans un ordre stable.
4.7.1 Préparer le flux
Flux en entrée : 1 ligne = 1 personne, avec champs Personnes + json_adresses.
4.7.2 Ajouter une clé constante
Pour forcer un unique regroupement : ajoute grp_json = "x" dans le tMap, puis groupe dessus.
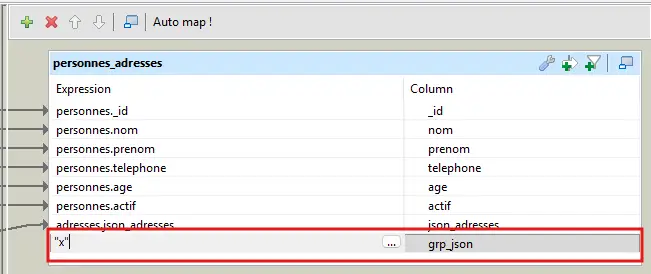
Pourquoi une constante ? Parce que le Group by ne produit qu’une sortie par valeur. En mettant la même valeur partout, tu garantis un seul document global sans logique métier cachée.
4.7.3 Trier pour un résultat stable
tSortRow sur _id pour un JSON ordonné et reproductible.
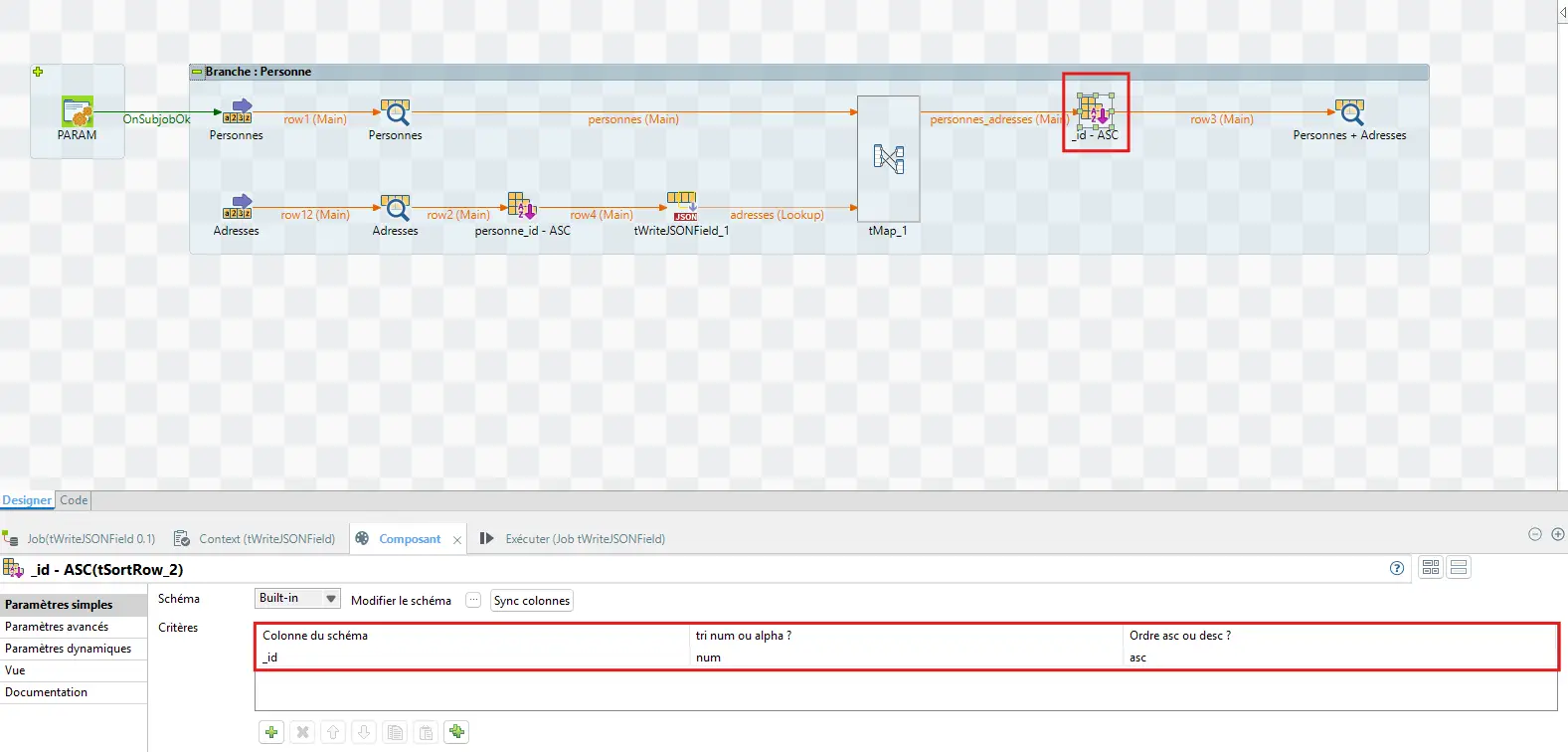
4.7.4 tWriteJSONField final
- Schéma de sortie :
json_final(String) +grp_json(pour leGroup by). - Output Column :
json_final.
4.7.5 Group by (une seule ligne)
Dans Basic settings > Group by :
Input column=grp_jsonOutput column=grp_json
Résultat : un seul JSON global.
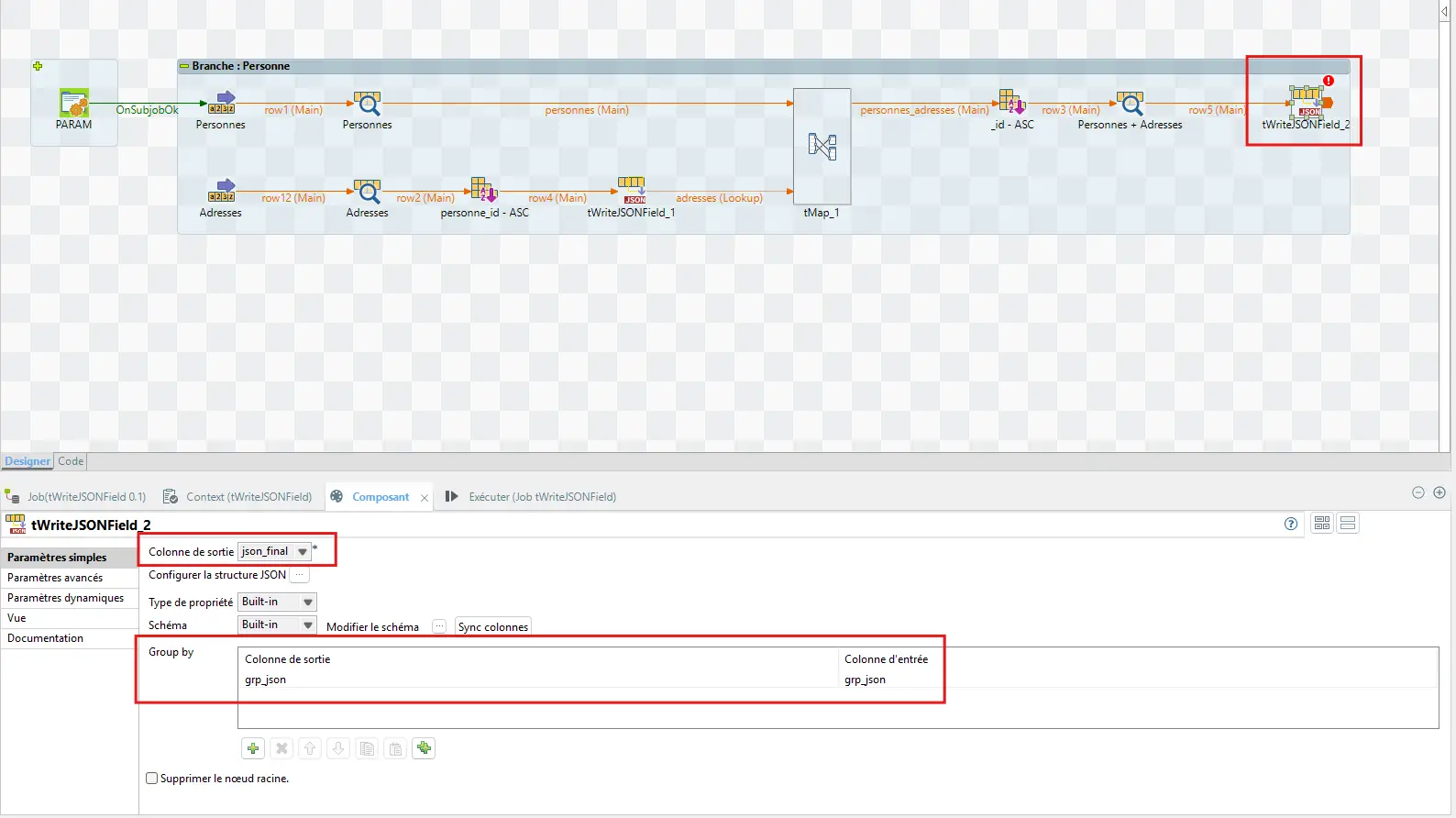
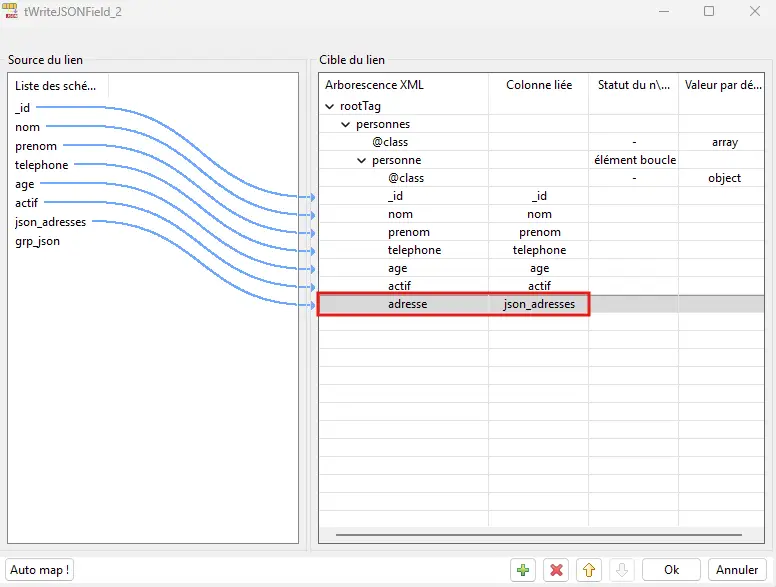
4.7.6 Configurer le JSON Tree final
Structure attendue : racine → personnes (class=array) → personne (loop, class=object) → champs + adresses (mappée depuis json_adresses).
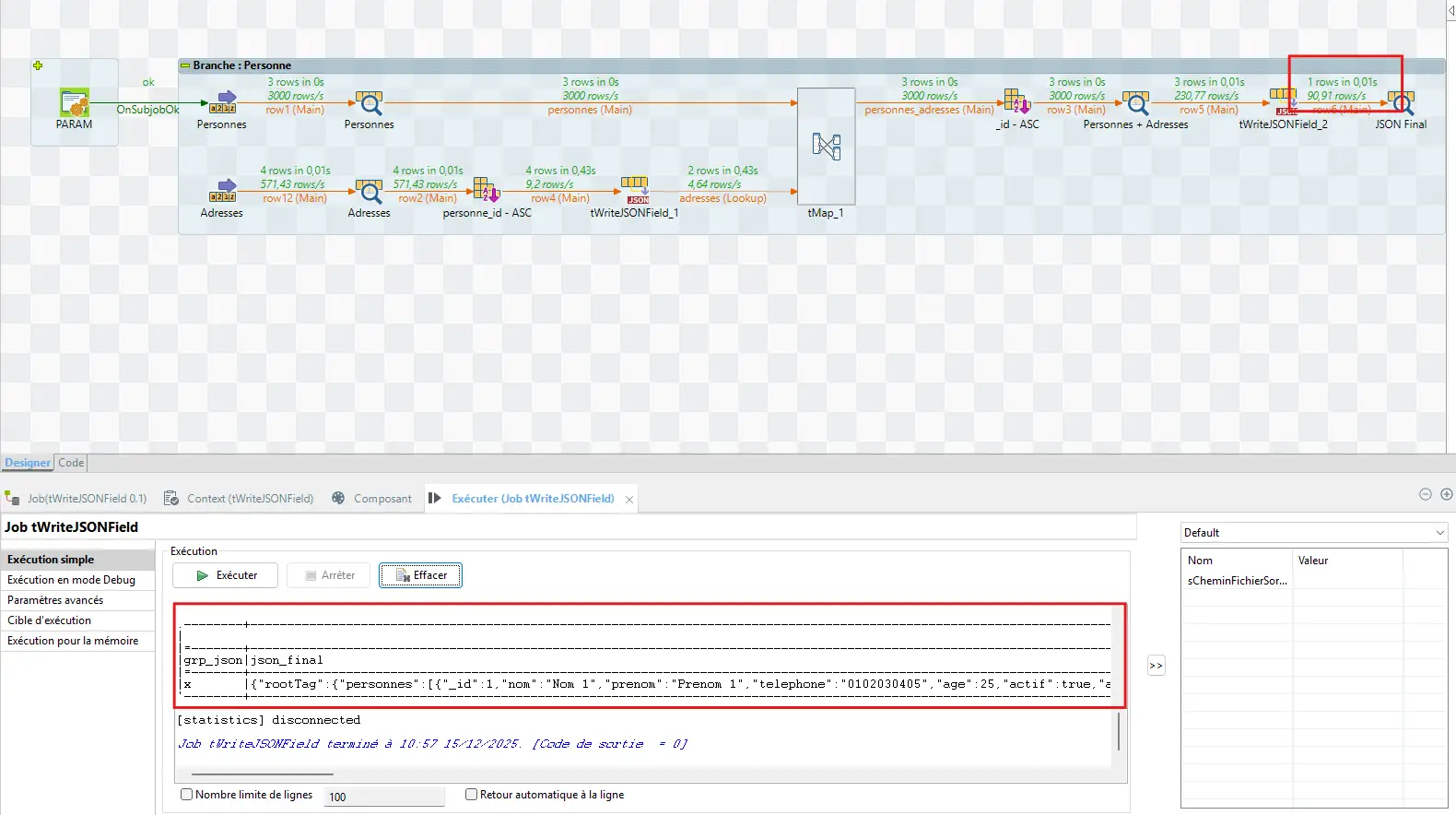
4.7.7 Vérifier le résultat
tLogRow en sortie :
- 1 seule ligne,
json_finalrempli,personnesavec tous les enregistrements,adressestableau (vide si besoin).
4.7.8 Écrire le fichier JSON
Ajoute un tFileOutputRaw et écris uniquement json_final (filtre la colonne grp_json avant avec le composant tFilterColumn).

5. Rétrospective et mise en perspective
5.1 Ce que nous avons construit
Si tu reprends le job dans l’ordre, on a fait exactement ça :
- Comprendre le rôle réel de
tWriteJSONField: composant déclaratif basé sur le JSON Tree, pas magique ; - Penser JSON avant Talaxie : on définit la structure cible, puis on construit le job ;
- Maîtriser les notions clés :
loop element,class=array/object,typequand le schéma ne suffit plus ; - Appliquer une méthode robuste :
- Étape A : résoudre le
1..n(Personne → Adresses) en amont, - Étape B : rattacher sans dupliquer,
- Étape C : produire un JSON global unique et stable.
- Étape A : résoudre le
Résultat : aucune duplication, tableaux cohérents (même vides), JSON lisible et exploitable.
5.2 Règles d’or
- Le Group by de
tWriteJSONFieldne trie jamais : tri préalable obligatoire. - Un JSON mal conçu vient souvent d’un flux mal structuré : on corrige le flux avant le JSON Tree.
- Un tMap trop tôt aplatit et complique : tu reconstruis ensuite ce que tu viens de détruire.
- Un bon JSON commence par une structure cible claire : le JSON Tree la traduit, rien de plus.
5.3 À adapter selon ton contexte
Cet article a un objectif : t’aider à comprendre et maîtriser ce que tu fais.
Dans la vraie vie, tu adaptes toujours selon le besoin :
- API REST : souvent un JSON par entité/appel, structure stricte, types obligatoires.
- Base NoSQL : documents unitaires ou agrégés selon les usages ; attention à la volumétrie.
- Échanges batch/fichiers : JSON global pertinent tant que les volumes sont maîtrisés.
La bonne question n’est jamais « Comment faire ce JSON avec Talaxie ? » mais :
« Quel JSON la cible attend-elle vraiment ? »
5.4 Mot de la fin
Avec
tWriteJSONField, la qualité du JSON dépend surtout de la réflexion en amont… puis de la configuration.
Une fois cette logique acquise, générer des JSON complexes devient :
- plus simple,
- plus fiable,
- et beaucoup moins frustrant.
👉 À partir de là, tu peux :
- adapter cette méthode à tes flux,
- changer la granularité (1 JSON par ligne ou global),
- intégrer ces JSON dans des API, bases NoSQL ou pipelines plus larges.