Pour reproduire exactement ce cas, j’ai mis à disposition sur GitHub les éléments suivants :
- 📦 Un workspace Talend prêt à l’emploi
👉 [Le Workspace est ici] pour suivre le pas-à-pas.- 📄 Les fichiers CSV d’exemple, dans le même repo (dossier
FICHIERS_EXEMPLES).
Le vrai danger : la donnée “presque correcte”
Dans un projet data, le vrai problème n’est pas la donnée manquante.
Le vrai danger, c’est la donnée presque conforme :
- une date dans “un autre” format,
- un entier stocké en texte,
- un champ obligatoire parfois vide,
- un booléen “à peu près”.
Et le jour où ça casse… ça casse en production, souvent loin de la source, et toujours au pire moment.
L’objectif de cet article est simple :
Dans un pipeline sérieux, tu laisses passer uniquement ce qui respecte le contrat.
Le reste doit être rejeté.
C’est précisément le rôle de tSchemaComplianceCheck : reprendre le contrôle dès l’entrée et protéger la PROD.
1. tSchemaComplianceCheck : ce que c’est, et surtout ce que ce n’est pas
tSchemaComplianceCheck est un composant de contrôle de conformité.
Son rôle est clair :
Vérifier que la donnée reçue respecte le schéma attendu (types, formats, contraintes)… puis trier.
Points clés à bien comprendre :
✅ Il ne “répare” pas la donnée
✅ Il ne “devine” pas
✅ Il applique un contrat, puis sépare
Ce que le composant contrôle
Selon ta configuration, il peut valider :
- le type (String, Integer, Date, Boolean…),
- la nullabilité,
- la taille / longueur,
- le format des dates.
Et surtout, il génère deux flux distincts :
- Main → conforme : le pipeline continue,
- Reject → hors-contrat : tu mets de côté (et tu exploites).
👉 Le découplage Main / Reject est la vraie valeur de ce composant.
2. Le pattern Talaxie : “Lire large, valider strict”
Dans la vraie vie, tu reçois des fichiers “sales”.
Le piège classique :
- soit être trop strict dès la lecture → le job plante,
- soit être trop permissif → tout passe, et tu construis une usine à gaz plus loin.
Le bon pattern est toujours le même :
- Lecture tolérante → ne jamais planter à la lecture
- Validation stricte → ne jamais polluer le pipeline
- Rejet exploitable → jamais une poubelle
👉 Un pipeline complexe mérite des données simples, propres et prévisibles.
La permissivité n’est pas de la robustesse.
La robustesse, c’est savoir dire non.
3. Les modes de configuration (et comment choisir)
3.1 Contrôle basé sur le schéma d’entrée
Le contrôle s’appuie directement sur le schéma entrant.
✅ Rapide à mettre en place
⚠️ Peu utile si ton schéma d’entrée est permissif (ex. tout en String)
3.2 Règles personnalisées
Tu définis manuellement les règles colonne par colonne.
✅ Bien pour quelques champs critiques
⚠️ Maintenance plus lourde dans le temps
3.3 Schéma de test (recommandé)
C’est l’approche la plus propre et la plus industrialisable.
Principe :
- le schéma d’entrée est tolérant (souvent 100 % String),
- le schéma de test représente le contrat métier strict,
tSchemaComplianceCheckvalide la compatibilité.
✅ Lecture sans blocage
✅ Contrat métier explicite
✅ Rejets exploitables
👉 C’est le pattern à privilégier dans la majorité des projets Talaxie.
4. Cas concret : protéger la PROD avec un contrat strict
4.1 Les fichiers reçus
On reçoit deux fichiers :
personnes.csvadresses.csv
Ils contiennent tout ce que tu connais :
- séparateur
;, - formats incohérents,
- champs vides,
- types non respectés,
- valeurs “humaines” (
yes,1,FALSE, …).
👉 Exactement le genre de fichiers qui passent “presque toujours”… jusqu’au jour où non.
4.2 Le pipeline naïf (et pourquoi il est dangereux)
Le pipeline naïf, c’est :
- soit rejeter trop tôt → plus rien ne rentre,
- soit tout laisser passer → dette technique assurée.
Trop strict dès la lecture
Un schéma d’entrée trop strict peut :
- faire planter le job,
- bloquer un traitement,
- provoquer un incident en PROD.
Oui, certains composants d’entrée possèdent un flux Reject.
Mais :
- tous ne se comportent pas pareil,
- ce n’est pas leur rôle principal.
👉 tSchemaComplianceCheck est fait pour ça : poser un contrôle cohérent, reproductible et exploitable.
Trop permissif
À l’inverse, tout laisser passer, c’est :
- gérer des cas particuliers partout,
- complexifier les
tMap, - rendre le job fragile.
4.3 Le pipeline robuste (recommandé)
La bonne pratique est simple :
laisser entrer, puis trier.
- Lecture tolérante
tFileInputDelimited- schéma permissif (String)
- Contrôle de conformité
tSchemaComplianceCheck- schéma de test = contrat métier
- Deux routes
- Main → données conformes,
- Reject → données hors-contrat.
Résultat :
- aucun crash à la lecture,
- pipeline stable,
- anomalies isolées très tôt,
- traitement aval simplifié.
4.4 Pas à pas : intégrer tSchemaComplianceCheck dans ton job
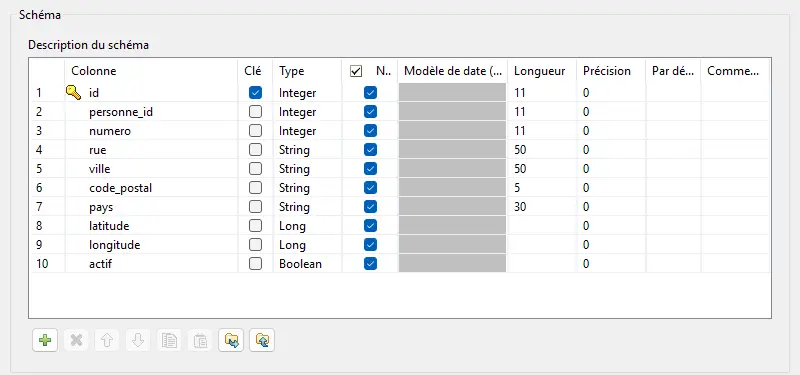
Pré-requis — Définition des schémas d’entrée
Personnes
On va créer un schéma d’entrée tolérant (tout en String).
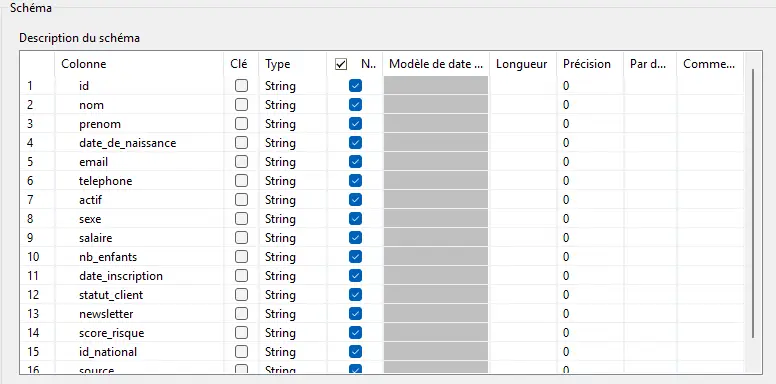
Ce schéma est utilisé pour la lecture dans le
tFileInputDelimited.
On va également construire un schéma de contrôle, beaucoup plus strict : le contrat métier.
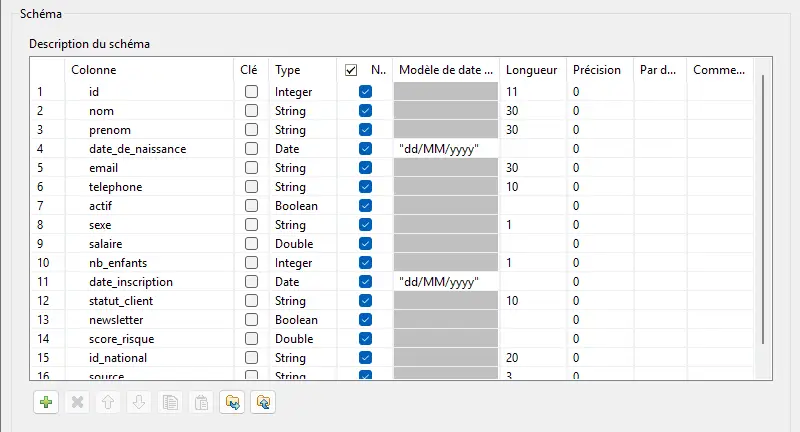
Ce schéma est utilisé pour le contrôle et pour les traitements aval.
Adresses
On applique exactement la même logique que pour personnes.csv.
Schéma d’entrée tolérant (tout en String) :
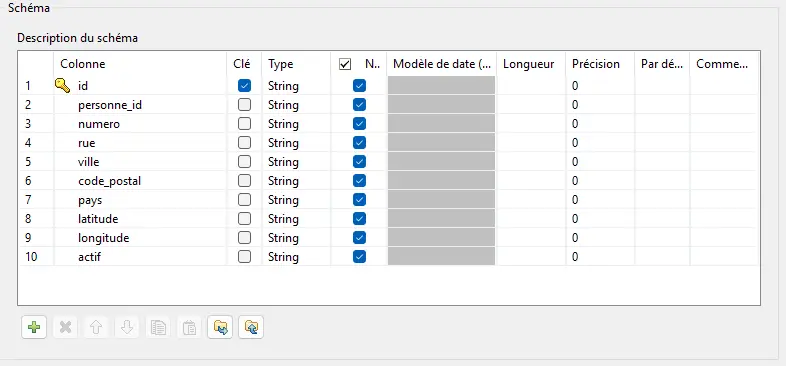
Schéma strict (contrat métier) :
Étape 1 — Lecture tolérante de personnes.csv
- Ajoute un
tFileInputDelimited, - Séparateur
;, - Header = 1,
- Encodage UTF-8,
- Schéma : permissif (tout en String).
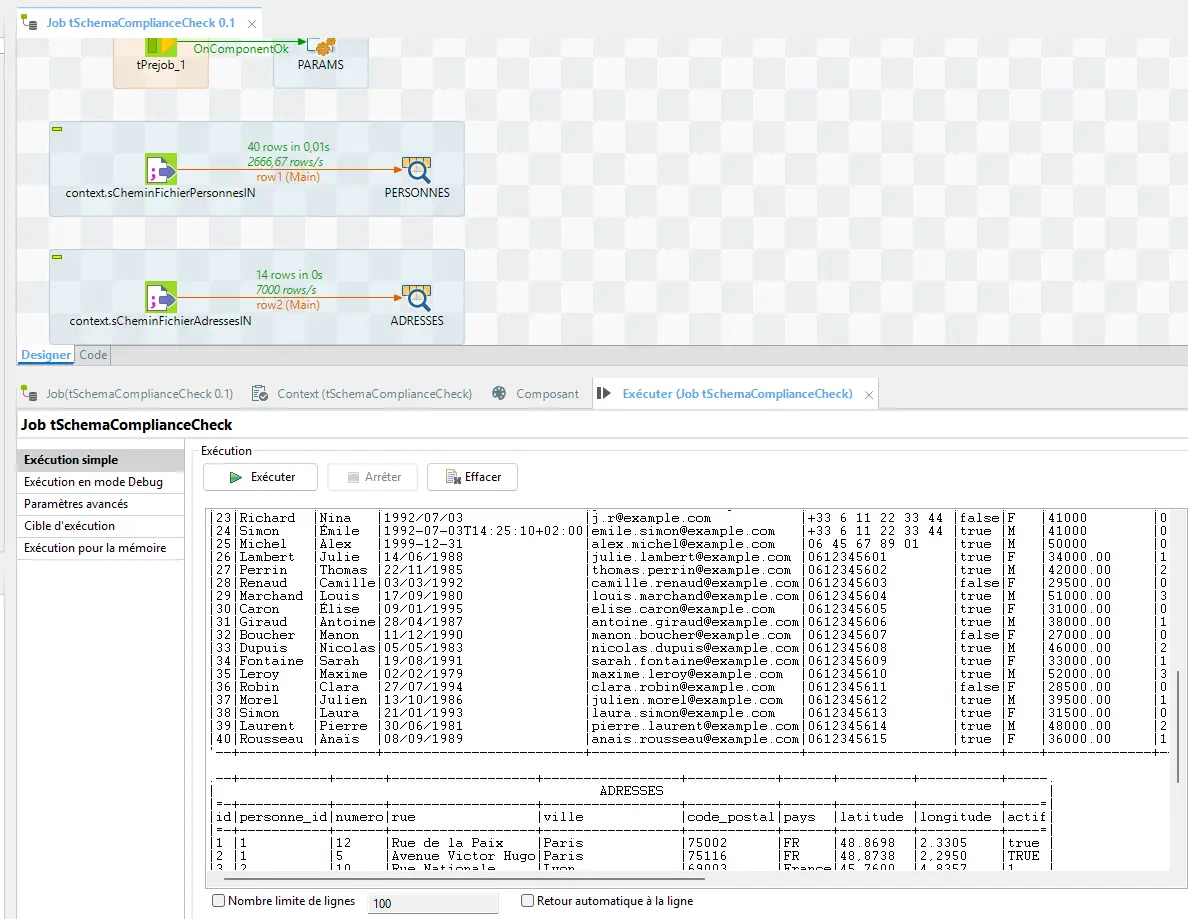
Étape 2 — Lecture tolérante de adresses.csv
Effectue exactement la même configuration que pour l’étape 1, mais avec le fichier adresses.
Normalement, tu devrais obtenir quelque chose qui ressemble à ceci :
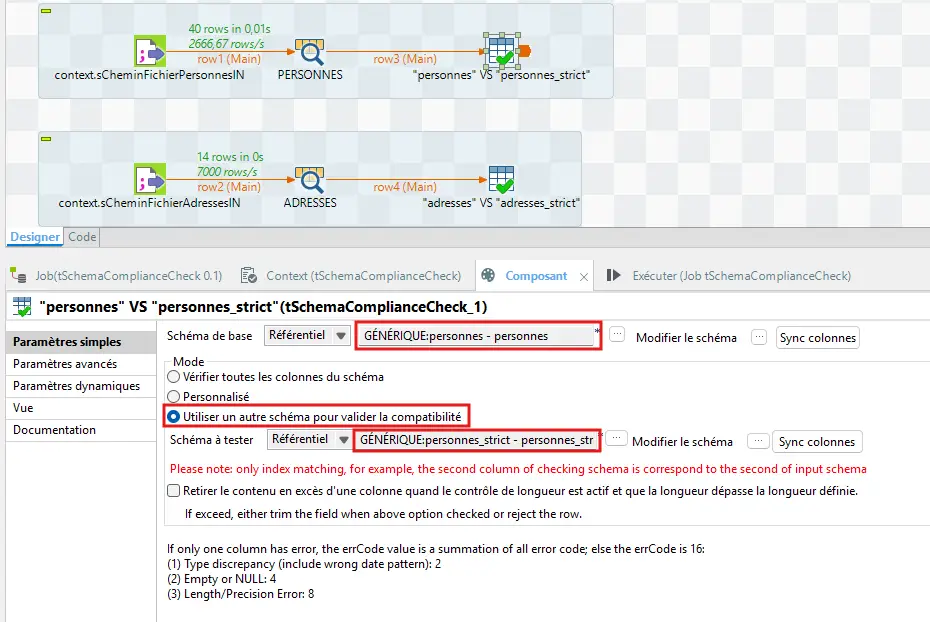
Étape 3 — Ajouter tSchemaComplianceCheck
Pour tes deux sous-jobs, ajoute tSchemaComplianceCheck :
- Relie le flux Main,
- Active le schéma de test (contrat métier),
- Branche :
- Main → traitement normal,
- Reject → journalisation (
tLogRowici).
Configuration exemple (personnes) :
⚠️ Important :
tSchemaComplianceCheckne convertit pas les types.
Il vérifie uniquement la conformité.
La conversion réelle se fait après, viatConvertTypeoutMap.
Conversion du schéma Main vers le schéma strict :
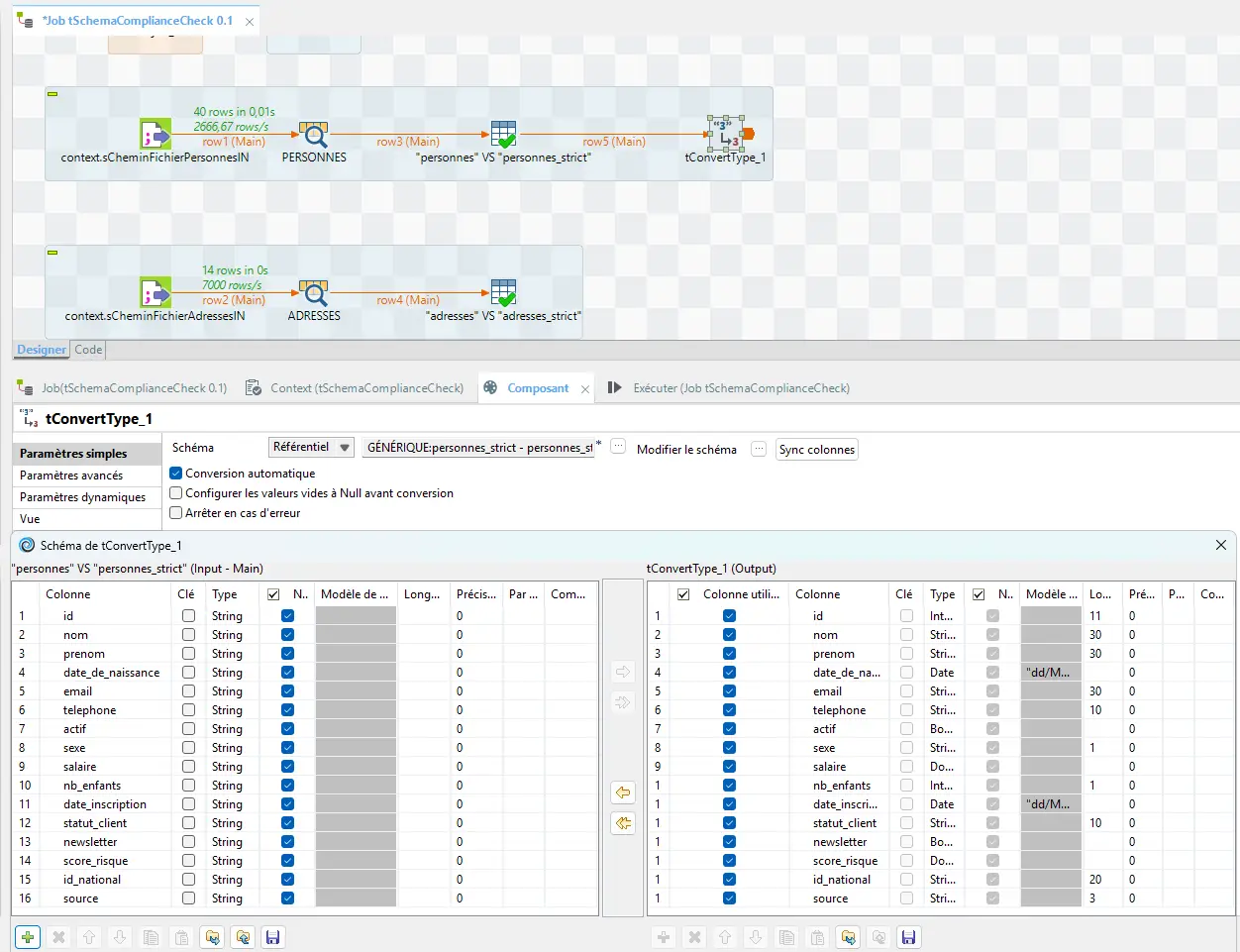
Pour le flux Reject, reste en Built-in :
errorCode et errorMessage sont ajoutés automatiquement par le composant tSchemaComplianceCheck.
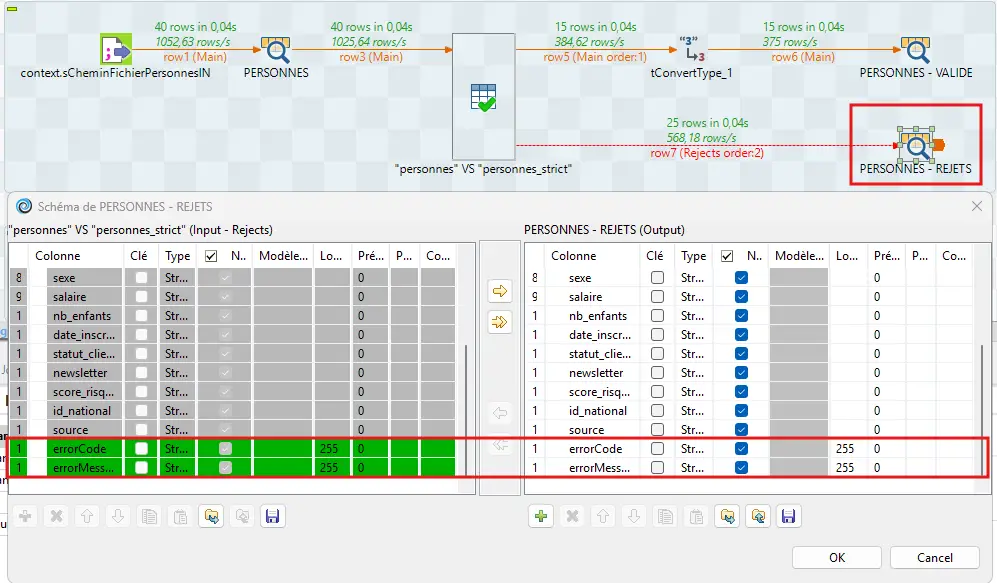
Cette configuration est un exemple.
Il n’existe pas de configuration universelle : le contrat dépend toujours du pipeline aval.
Étape 4 — Exploiter le Reject
Pour l’instant, les rejets sont affichés via un tLogRow.
Tu peux ensuite les utiliser pour :
- log technique,
- fichier d’erreurs,
- analyse qualité,
- process de correction séparé.
4.5 Exemple de contrat strict sur la date (zéro tolérance)
Dans ce cas concret :
date_de_naissancedoit être au formatdd/MM/yyyy,- un seul format accepté,
- toute autre valeur est hors-contrat et part en Reject.
⚠️ Une date “compréhensible” ne suffit pas.
Une date valide est une date compatible avec le pipeline aval.
👉 Oui, ça génère des rejets.
👉 Et c’est exactement le but : protéger la PROD.
5. Et si tu veux corriger les données ?
Maintenant que tu sais router les rejets, tu peux mettre en place un process séparé pour les corriger.
Tu obtiens deux pipelines :
- Pipeline PROD → strict, protecteur,
- Pipeline de normalisation → à part.
Avantage :
une séparation claire des responsabilités, et une production sécurisée.
Le mot de la fin
tSchemaComplianceCheck n’est pas optionnel.
C’est un point de contrôle stratégique.
Lire large, valider strict.
Si tu laisses passer des données “presque conformes”,
tu prends une dette technique…
et tu la paieras en production.
👉 Tu passes d’un ETL qui subit…
à un ETL qui protège la PROD.
—